在上篇文章,我們提到到了在機器學習中模型學習的方式,今天就要來探討機器學習這個「學習」的過程,以及模型如何去進行「訓練」,而這當其實就是一連串的流程,也稱為機器學習的生命週期 ( Life Cycle ),其主要分成 7 個步驟。
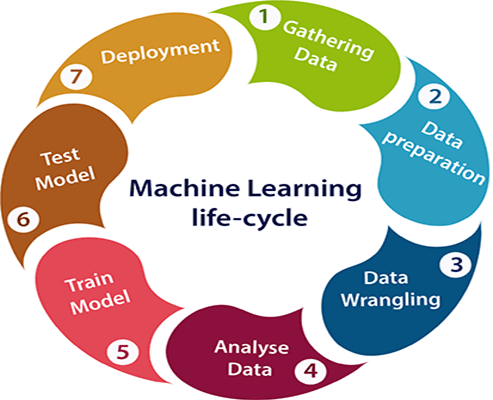
整個生命週期主要會進行 7 個階段,如下:
在這個步驟主要就是進行下面三個部分:
像是若要模型能夠分辨出各種動物,就需準備很多種動物的圖片,若要能夠做出疾病的預測,就會需要醫療儀器等來幫助我們獲取人體的各種資訊,像是血壓、脈搏、血糖等當作訓練模型的資料,資料採集的來源可以有很多種,可以是從網路上、資料庫或是行動裝置等地方獲取,所以我們開始收集資料前,應該要先了解問題的種類和需求,還有清楚你最終的目標為何 ( EX : 辨識貓狗 ),在根據這個目標去進行資料採集,並確認要收集哪些資料才能滿足目標的需求,而我們統稱這些收集到的資料為資料集 ( Dataset )。
在收集到資料後,我們要為之後的步驟做準備,而資料準備的步驟通常會針對下面兩個部分進行:
這個步驟是為了能夠確保收集到的資料是可用的 ( Useable )、乾淨的和殘缺值的清理,資料中的殘缺值或者所謂的資料噪音 ( Noise ) 都會降低模型的效能表現,而資料準備的主要的任務有:
進行到這個步驟的時候,經過前面幾個步驟,我們已有乾淨的資料可以用,分析資料主要會進行下面幾個部分:
上個步驟我們已經可以得到乾淨的資料集,並且讓模型輸出一個結果,在這個訓練模型的步驟中,我們通常會利用這個資料集當中的訓練集作為訓練資料,訓練資料顧名思義就是訓練時模型所用的資料,然後我們通過一次次的迭代訓練,模型會根據訓練資料不斷地去改善其輸出的表現,我們會先設定一個迭代次數讓模型去訓練,在每次的迭代中通常會用一些算法,例如梯度下降 ( Gradient Descent ),讓模型能在不斷迭代的過程中更新模型參數 ( Parameter ) 以改善模型效能,所謂的訓練模型,就是模型不斷改進增強效能的過程。
剛才我們用整個資料集中的訓練集去訓練模型,在這個步驟中,就會用資料集中的驗證集去測試模型在每次迭代 ( 訓練 ) 的效能表現,如果效能不佳的話就可藉此去調整模型參數改善,最後整個訓練過程結束後,就會用資料集中的測試資料來做最終的測試,在測試資料上的表現會體現出模型最終的效能與泛化能力,就可藉此來評估模型的好壞。
在這步驟就是要對模型做所謂的佈署,就是將經過訓練和測試評估後的模型應用到實際的生產環境中,所謂實際生產環境它可以是一個交互的平台,像是若你在電商平台中,用你訓練好的模型做一個 AI 服務,就要讓這個模型可以被佈署成 API,網站開發人員就可直接透過 API 使用到這個模型的功能,並將其併入到應用程式中,在後面的文章中我將會展示如何把訓練好的模型佈署在以 Django 為後端的網頁上。
以上就是機器學習大致上會經過的流程,從一開始資料的準備,到訓練模型、評估模型效能、最後再佈署模型,這就是機器學習典型的生命週期,資料的採集、準備、整頓是做好機器學習的基石,所以在明天我將會針對資料處理的部分做介紹,會用到 Python 的資料處理分析大神 - Pandas,那我們就下篇文章見 ~
https://www.javatpoint.com/machine-learning-life-cycle

